Metadata คืออะไร บอกอะไรเกี่ยวกับชุดข้อมูลนั้น ๆ บ้าง
Metadata คือข้อมูลที่อธิบายชุดข้อมูล เพื่อให้เข้าใจได้เบื้องต้นว่าเป็นชุดข้อมูลเกี่ยวกับอะไร ประเภทไฟล์ วันที่สร้างและปรับปรุง


Metadata คือข้อมูลที่อธิบายชุดข้อมูล เพื่อให้เข้าใจได้เบื้องต้นว่าเป็นชุดข้อมูลเกี่ยวกับอะไร ประเภทไฟล์ วันที่สร้างและปรับปรุง
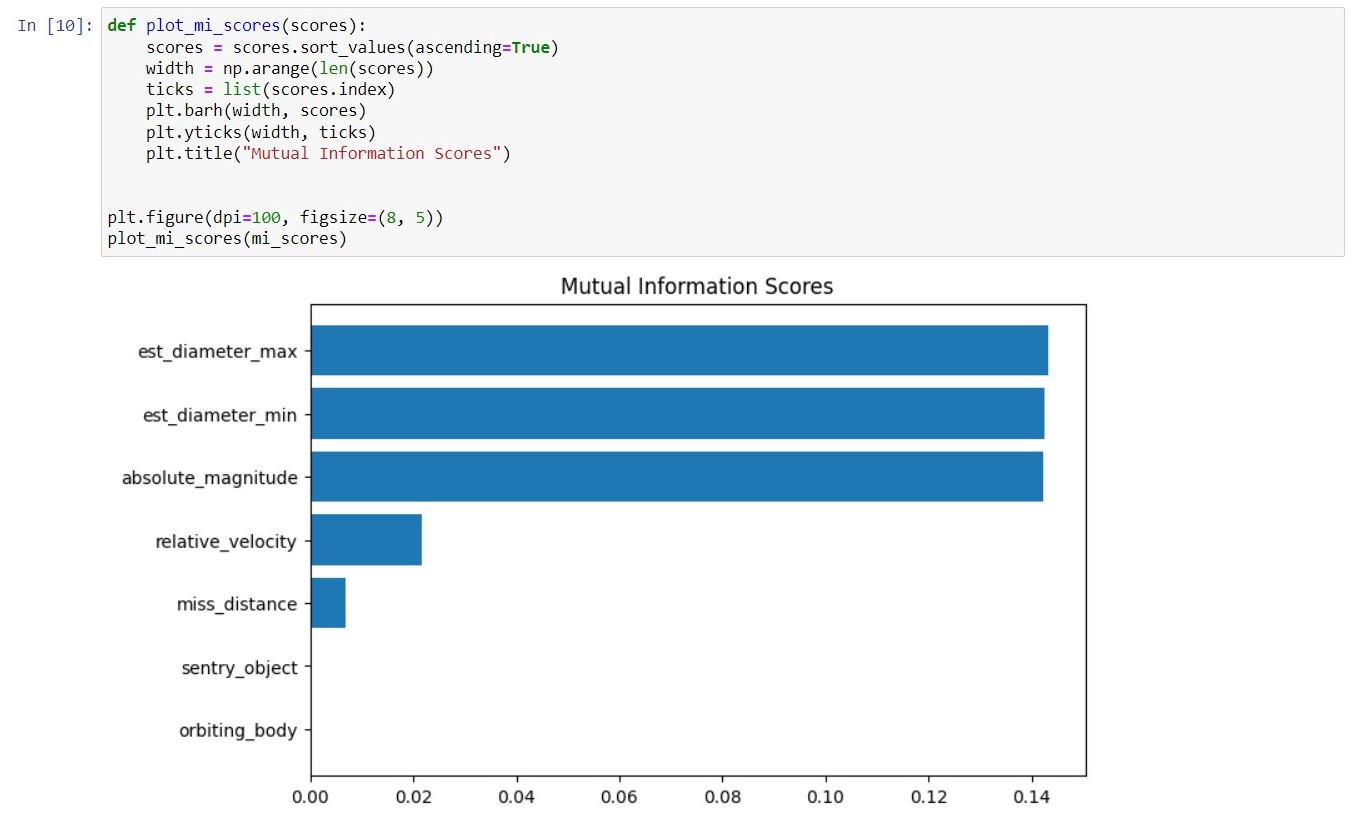
การทำงานด้าน Machine Learning นั้นจะต้องเจอข้อมูลและมีคำถามเสมอว่าควรเริ่มจากอะไรดี โดย Mutual Information เป็นหนึ่งในขั้นตอนที่แนะนำให้ทำ

วิธีการแปลงข้อมูลประเภทหมวดหมู่/ประเภท (ที่เป็นตัวอักษร) ให้เป็นชุดตัวเลขด้วยวิธีการ One Hot Encoding เพื่อให้โมเดลสามารถเรียนรู้ได้

การเรียนรู้เชิงลึก (Deep Learning) นั้นเป็นเทคนิคที่มัประสิทธิภาพมากในงาน Machine Learning ปัจจุบันซึ่งเบื้องหลังของมันก็คือการใช้ ANN
ในหลาย ๆ ชุดข้อมูลมักจะมีการเก็บวันที่ไว้ด้วยเสมอ ซึ่งการ Parsing Dates จะช่วยให้ใช้งานวันที่เหล่านั้นได้ง่ายยิ่งขึ้น

การจะเริ่มทำโปรเจคอะไรสักอย่างสิ่งที่ขาดไม่ได้เลยคือข้อมูล แล้วยิ่งเป็นงานที่เกี่ยวข้องกับ Data แล้วนั้น Data source จึงเป็นสิ่งจำเป็นมาก